
具有自适应微调策略的分层BERT,用于文档分类
具有自适应微调策略的分层BERT,用于文档分类
中科院一区
摘要
预训练语言模型(PLMs)已经取得了令人印象深刻的成果,并已成为各种自然语言处理(NLP)任务的重要工具。然而,当文档长度超过PLM的最大可接受长度时,将这些PLM应用于文档分类存在一个限制,因为在这些模型中会截断多余的部分。如果关键字在截断的部分,则模型的性能下降。为了解决这个问题,本文提出了一种带有自适应微调策略的分层BERT (HAdaBERT)。它由基于bert的局部编码器模型和基于注意力的门控记忆网络作为全局编码器组成。与直接截断文档的现有plm相比,所提出的模型使用文档的一部分作为区域,将输入文档划分到几个容器中。这允许本地编码器提取每个容器中的有用信息,并由全局编码器根据其对分类的贡献进行组合。为了进一步提高模型的性能,本文提出了一种自适应微调策略,该策略动态地决定需要微调的BERT层,而不是对每个输入文本的所有层进行微调。在不同语料库上的实验结果表明,该方法在文档分类方面优于现有的神经网络。
引言
文件中的重要信息可能会在不同的地方分发。句子之间的语义关系更加复杂和模糊,使得文档分类成为一项具有挑战性的任务。cnn在计算机视觉方面取得了成功,也被用于文档分类。假设文档中的每个token对分类的贡献不相等,自动对齐文本和强调重要token的过程、自注意力、动态路由已经被提出进一步提高cnn、GRU和LSTM网络的性能。此外,还提出了分层关注网络[15]用于文档分类,在句子级和文档级执行语义建模,然而这可能会导致token在句子上下文中的句法依赖性。
最近,预训练语言模型: BERT、ALBERT [17] 、 RoBERTa [18]成功地完成了各种NLP任务。在处理下游任务时,这些plm消除了从头构建模型的需要,并且可以采用transformers,self-attention mechanisms利用迁移学习学习高质量的文本语境表征。通常,首先向plm提供大量未注释的数据,然后通过屏蔽语言模型或下一个句子预测进行训练,以学习各种单词的用法以及该语言的一般编写方式。然后,模型被转移到另一个任务,在那里它们被馈送到另一个较小的任务特定数据集。对于文档分类,输入序列可以很长,但BERT模型的最大输入长度在大多数情况下是有限的[20]。一旦文档超过预设的最大输入长度,这些文档的多余部分将被直接截断。最佳短语和强烈推荐短语中的强烈主观短语将被截断,这可能导致模型的错误分类。
将BERT应用于文档分类的另一个明显问题是计算消耗。也就是说,随着输入序列长度的增加,对计算资源的需求急剧增加,因为微调每个变压器层的时间复杂度相对于输入长度呈指数增长。
本文提出了带自适应微调策略的分层BERT模型 hierarchical BERT model with an adaptive fine-tuning strategy来解决上述问题。HAdaBERT模型由两个主要部分组成,以分层方式对文档表示进行建模,包括局部和全局编码器。考虑到文档具有自然的层次结构,即一个文档包含多个句子,每个句子包含多个单词,我们使用局部编码器学习句子级特征,而全局编码器将这些特征组合为最终表示。与现有的plm直接截断文档到最大输入长度相比,提议的HAdaBERT使用文档的一部分作为区域,而不是使用一个句子作为一个区域。我们引入了一个容器划分策略来获得有效的本地信息,从而保留语法依赖关系。这样,容器中的关键信息和会被提取到局部编码器。全局编码器使用基于注意力的门控记忆网络学习顺序组合容器之间的语法关系。通过在分层体系结构中使用这两种编码器,该模型可以有效地捕获长文档中的本地信息和长期依赖关系。此外,提出了一种针对每个输入样本的自适应微调策略,该策略网络可以自适应地选择最佳的BERT微调层,以提高模型在训练和推理过程中的性能。这种策略是一种自动的通用方法,可以扩展到其他预训练的语言模型。
在多个语料库上进行了实证实验,包括AAPD、Reuters、IMDB和Yelp-2013数据集。对比结果表明,所提出的HAdaBERT模型在文档分类方面优于现有的几种神经网络。此外,该模型可以有效地解决以往文档分类方法的局限性。它也与现有的学习短句表示的模型竞争。另一个观察结果是,自适应微调策略通过动态选择微调层来实现最佳性能改进。
本文的其余部分组织如下。第二节介绍和回顾了文献分类的相关工作。第3节描述了提出的分层BERT模型和自适应微调策略。对比实验在第4节中进行。最后,在第5部分得出结论
相关工作
文档级分类是自然语言处理中的一项基本任务,也是一项具有挑战性的任务。本节简要回顾现有的文档级分类方法,包括传统的、分层的和预训练的神经网络。
Conventional neural networks传统神经网络
通常用于文档分类任务的深度神经网络模型有cnn[23-25]和rnn[9,26]。这些模型将文档表示为具有语义和语法信息的分布式表示。
rnn中的梯度爆炸/消失问题可能导致模型无法捕获长期依赖关系。为了解决这个问题,LSTM[29]和GRU[10]网络使用允许显式内存更新和传递的内存单元。这两种模型都学习上下文信息,这些信息有助于捕获长文本的语义。此外,Tai等[11]提出了一种根据依赖解析树合并语法信息的树- lstm网络。Zhou等人[30]提出了一种循环CNN (RCNN)模型,该模型扩展了现有的卷积层作为循环架构。Yang等人[4]提出了一种序列到序列模型,用于捕获多标签文档分类中多个标签之间的内在关系。此外,记忆网络[31-33]引入了一种类似于LSTM网络的存储单元的外部存储器,能够存储长文本的信息。
引入了注意机制[12]来选择重要信息,从而提高模型的性能。注意机制能够捕获文本的重要信息,从而更好地学习文本表示,并且可以很好地与各种神经编码器配合使用。考虑到这种方法,Zheng等[37]提出了一种基于自交互关注的文档分类机制。注意机制有两个局限性。首先,它无法感知位置信息,导致无法学习句子内的高级语言特征,如表达的转变或递进表达。此外,当上下文中其他不太重要的单词数量增加时,在很长的文档中强调关键字可能会有困难,因为通过注意机制分配的关键字的权重会被稀释,并且在模型训练期间难以利用。
Hierarchical neural networks层次神经网络
近年来,层次神经网络[15,38]被广泛用于文档分类。为了获取句子间的句法信息,Tang等[38]设计了一种分层架构,使用CNN和LSTM网络结合词嵌入学习文档表示,然后采用GRU网络对文档内的句法信息进行编码。Xu等人[39]提出了一种缓存LSTM模型,该模型应用了一组具有不同遗忘门的LSTM细胞。遗忘率高的门可以学习局部特征,遗忘率低的门可以捕捉全局特征。为了将自注意机制扩展为层次结构,Yang等人[15]提出了一个在句子和文档两个层次上都有注意机制的层次模型。Yin等[42]将任务作为理解问题,提出了一种分层交互的基于注意力的模型来构建文档表示。此外,对于产品评论,一些研究证明,将情感信息与额外的特征(如用户和产品消息)结合起来,对于最终的极性分类是有用的[43-45]。
Pretrained neural networks预训练神经网络
通过使用自关注机制,transformer[19]不能直接使用GRU和LSTM网络的顺序结构,但是允许模型并行训练。为了进一步改进transformer,Gong等[46]提出了多头注意力算法,并将分层结构引入自注意力机制。但是,转换器可能会忽略文本的本地依赖关系和时间关系。随着序列长度的增加,变压器的存储和计算复杂度迅速增加。
已经提出了几种用于文本分类的transformer预训练语言模型(plm)[16,47]。其基本思想是利用大量未标记的数据,通过无监督mask语言模型或下一句预测对语言模型进行预训练学习句法和语义信息,利用这种方法,Adhikari等[20]首先引入了BERT模型[16],采用截断策略作为DocBERT进行文档分类,取得了良好的性能。Liu等[18]提出了RoBERTa,它使用快速微调的BERT训练程序,成功地使用分段预测进行文档分类,并显示出改进的结果,Lan等[17]提出了ALBERT模型,该模型引入了分解嵌入参数化和跨层参数共享两种参数约简技术,降低了内存消耗,提高了训练速度。
对于文档分类,现有的plm受到输入长度的限制。使用截断策略时,模型会丢失一部分用于分类的信息,当重要的内容落在被截断的部分时,会产生深远的影响,降低文档分类模型的性能。另一个问题是,基于bert的模型的预训练和微调都会产生相当大的计算资源成本。随着输入长度的增加,消耗的资源急剧增加,注意力权重被稀释。

Hierarchical BERT with adaptive fine-tuning
具有自适应微调的分层BERT
它由两个主要部分组成,以分层方式对文档表示进行建模,包括本地和全局的编码器,输入文档首先被分成几个容器。在每个容器中,基于bert的模型被微调以提取高质量的局部特征。以连续的局部特征为输入,采用基于注意力的门控记忆网络作为全局编码器,学习容器间的长期依赖关系。提出的HAdaBERT模型可以有效地捕获局部和全局信息用于文档分类。
微调BERT应用在局部编码,adaptive fine-tuning自适应调整BERT。
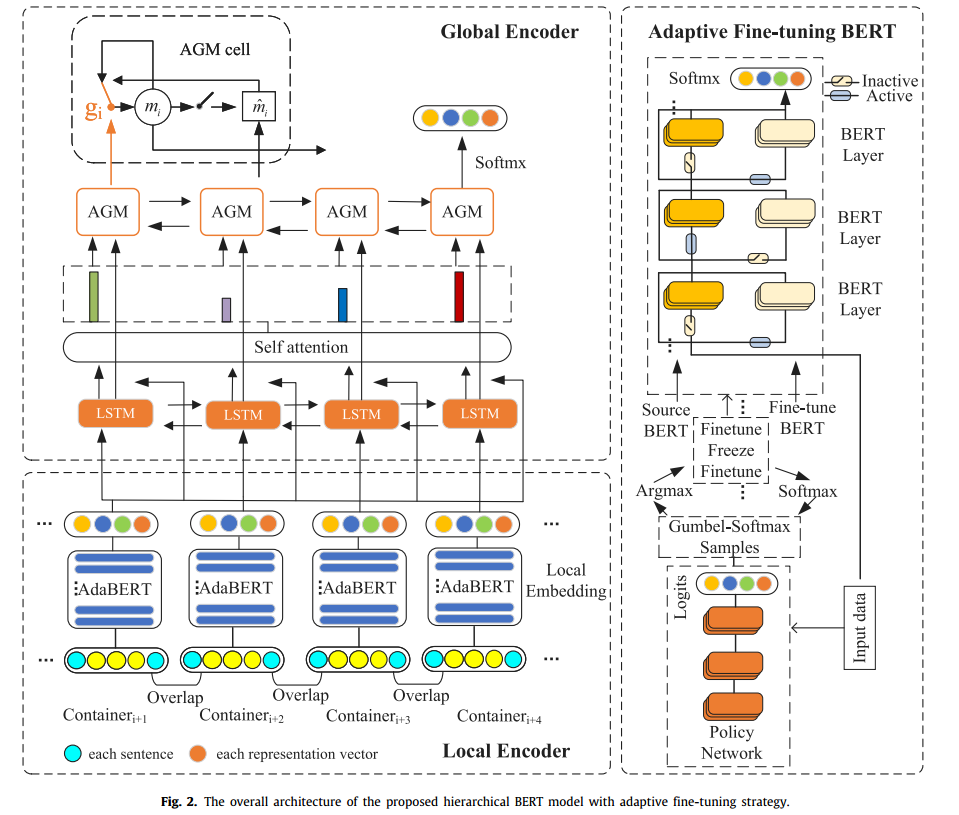
local encoder
对于每个给定的文档,将文档划分为v个容器,表示为D= [r1,r2, . . . ,rv]。每个容器又由一系列的token组成,
$$
r_{i} = [x_{i1},x_{i2},…,x_{ic}]
$$
其中c是容器的容量。在直观的区域划分策略中,将文档中的每个单独的句子作为一个区域。例如,由三个句子组成的文档有三个区域。这个简单的策略是非常不平衡的,因为一个大的句子长度边距,很长和很短的句子都出现在文档中。另一种简单的方法是将文档划分为固定长度的区域。这种策略破坏了文档中的语法关系,可能导致性能下降。
容器策略:几个固定容量c的容器基于容器尽可能多的装句子的想法装载句子。我们依次将句子放入容器中,直到文本长度超过容量c。不够的用0值填充到c。值得注意的是,我们在每个相邻的容器之间建立了一个重叠句子。也就是说,前一个容器的最后一句话和下一个容器的第一句话是相同的。这可以有效地链接这两个容器,使它们不是相互独立的,并且保留了语法依赖性。
为了提取每个容器中的局部特征,我们使用了预训练的语言模型BERT[16]。它在各种NLP任务中取得了令人印象深刻的表现。BERT由多层双向transformer编码器组成[19],通过无监督学习进行预训练,使用屏蔽语言模型(屏蔽率为15%)或下一句预测。特别地,我们使用了uncase BERT-based1模型,它包含12层transformers,隐藏大小为768。在每个容器中,首先在容器ri的开始和结束处分别添加两个特殊符号[CLS]和[SEP]。然后,我们将每个容器送入BERT模型以获得局部表示ti。
$$
t_{i}\in\mathbb{R}^{dt}
$$
$$
t_{i}=f_{BERT}([x_{i1},x_{i2},…,x_{ic}]:\theta _{BERT})
$$
其中xi1, xi2,。, xic是第i个容器r中令牌的输入序列。θBERT是BERT模型的可训练参数,为所有容器共享,然后在模型训练时进行微调;dt=768是局部表示的维数。
Global encoder
为了将所有局部特征顺序编码为文档表示,使用了基于注意力的门控记忆网络来捕获跨容器的远程依赖关系并对全局信息建模。[t1, t2, . . . , tv] as input,首先使用双向LSTM (BiLSTM)网络将局部表示映射到隐藏状态,表示为
$$
\underset{h_{i}}{\rightarrow} = LSTM(\underset{h_{i-1}}{\rightarrow},t_{i})
$$
$$
\underset{h_{i}}{\leftarrow} = LSTM(\underset{h_{i+1}}{\leftarrow},t_{i})
$$
$$
h_{i}=[\underset{h_{i}}{\rightarrow} ,\underset{h_{i}}{\leftarrow}]
$$
为了增强每个局部表示的信息,我们在BiLSTM的输入和输出之间添加残差连接,记为
$$
k_{i} = h_{i}\oplus t_{i}
$$
ki表示局部特征,\oplus 表示相加。
attention-based gated memory network (AGM)层。考虑到并非所有单词和句子对最终分类的贡献都是相同的,我们使用AGM层依次选择重要信息并将其整合到记忆中,以获得远距离关系并保留上下文信息。为了自动选择重要信息,我们使用自注意机制来学习每个局部表示ki的权重,其计算为
$$
e_{i} = tanh(W_{e}k_{i}+b_{i})
$$
$$
\alpha =\frac{exp(e_{i})}{\sum_{j=1}^{|D|}exp(e_{j})}
$$
其中,We和be分别表示与注意层相关的权重和偏差,αi是分配给第i个局部表示的权重。AGM层具有循环架构,这有点类似于内存网络。它使用记忆向量m∈R dm来记录局部表示中的重要信息,并使用门g来控制训练过程中需要保留或忘记的相关信息。AGM层的计算如下:
$$
g_{i}=\sigma (W_{i}k_{i}+U_{g}m_{i-1})
$$
$$
\hat{m}=tanh(W_{h}k_{i}+g_{i}\odot U_{h}m_{i-1})
$$
$$
m_{i}=(1-\alpha_{i}\odot m_{i-1}+\alpha_{i}\odot m_{i})
$$
权重αi用来控制保留多少过去的信息和吸收多少新的信息。
为了实现,我们应用了两个独立的AGM层对每一步序列的前向和后向信息进行建模。最后的记忆向量是AGM的两个方向的连接,它能够保存过去和未来的信息。我们将前向的最后一个记忆向量和后向的第一个记忆向量连接起来,生成用于最终分类的文档表示o。
$$
o= [\underset{m_{v}}{\rightarrow},\underset{m_{1}}{\leftarrow}]
$$
给定训练数据集{Dn, yn},分类是一个带有softmax函数的单层MLP。损失函数具有分类交叉熵
Adaptive fine-tuning strategy
自适应微调策略
对BERT中的所有层进行微调不一定会产生最佳性能。因此,我们使用policy network 选择BERT中需要在训练期间微调或冻结的层。等式1中BERT模型由L层transformer组成。
$$
f_{BERT}=[T1,T2,…,TL]
$$
该policy network表示如下:
$$
policy(r)=\left{s_{1},s_{2},…,s_{L}\right}, s_{i}\in \left{0,1 \right}
$$
如果si=1则对第i层微调,si=0则对第i层冻结。我们冻结了BERT中的原始的Ti,创建了一个新的可训练的层$$ \hat{Ti} $$。第i层的输出计算如下:
$$
d_{i} =s_{i}\hat{T_{i}(d_{i-1})}+(1-s_{i}T_{i}(d_{i-1})),d_{i}表示第i个BERT层的输出
$$
policy network由三层transformer组成,容器r的embedding表示作为输入,s的计算如下:
$$
e_{i} = Transformer(r),e_{i}只有两个元素
$$
$$
s_{i}=argmax(e_{i})
$$
ei是logit分布,si是离散分布,离散数据导数不适用很难反向传播。于是用的Gumbel-Softmax 。
Gumbel-Softmax是一种从离散数据中采样的方法一种允许定义离散分布的可微的近似抽样的形式的分布。GumbelSoftmax将离散值转换为连续值,从而在端到端反向传播时实现梯度计算和策略网络优化。具体的Gumbel-Softmax实现如下:
$$
s_{i}=softmax(\frac{log(e_{i}+G_{i})}{\iota }),\iota 越小s_{i}就越接近onehot向量
$$
$$
G_{i}=-log(log(u_{i}))
$$
Gi是一个随机变量服从独立的均匀分布。ui服从均匀分布U(0,1)
实验
数据集
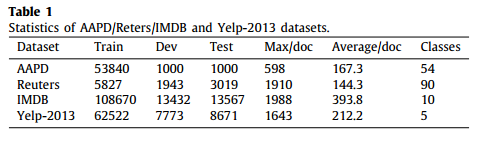
Dev是开发集也称为验证集,从训练集中分出一部分作为开发集,目的是用来选择模型,调整参数评估性能。
几个Baseline模型:

局部编码中容器容量c的影响:
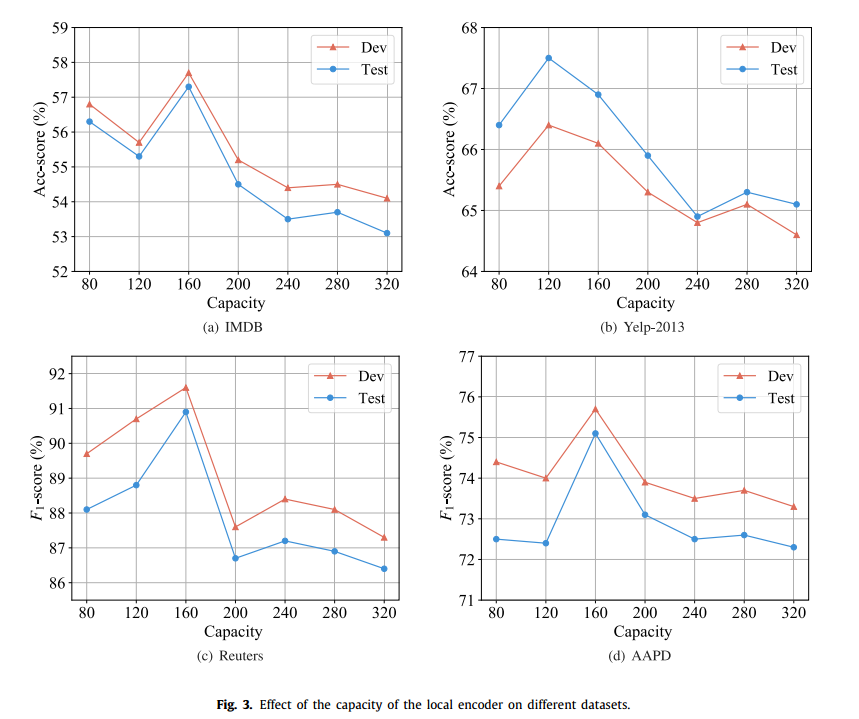
等实验说明了该模型的优越性。
未来
未来的工作将探索更有效的局部编码器,并引入强化学习来研究更好的微调策略。






